









»Die Entwicklung zum ›data driven‹ Unternehmen ist alternativlos«

Interview mit Frank Weber, Geschäftsführer Hitachi Vantara Deutschland.
 Mit welchen Schritten stellen Unternehmen sicher, dass sie Zugang zu besseren Daten haben und mehr aus ihnen herausholen können?
Mit welchen Schritten stellen Unternehmen sicher, dass sie Zugang zu besseren Daten haben und mehr aus ihnen herausholen können? Unser »digitaler Footprint« ist heute allgegenwärtig – und genauso verhält es sich auch mit den Daten, auf denen Unternehmen ihre »digitale Transformation« aufbauen. Je nachdem wie sie ihre Daten kontrollieren, darauf zugreifen und sie nutzen, können sie Informationen über neue Märkte erlangen und insgesamt effizienter werden. Entscheidend, um das digitale Potenzial zu maximieren, sind die Qualität und der Wahrheitsgehalt der Daten.
Allerdings ist bereits die Speicherung dieser Datenmengen eine Aufgabe, vor denen es vielen graut. Es erfordert eine Menge Intelligenz, Daten so zu organisieren, dass sie gefunden und genutzt werden können. Nach unseren Schätzungen sind heute rund 80 Prozent der Daten unstrukturiert und über das gesamte Unternehmen verstreut. Hier gilt es, einerseits Struktur in die unstrukturierten Daten zu bringen und andererseits zu akzeptieren, dass die Daten verteilt sind. Mit einem zentralen Repository lassen sich beispielsweise Daten aus verschiedenen Quellen integrieren, vernetzen und einsammeln, einschließlich strukturierter und halbstrukturierter Daten. Verantwortliche sollten sich auch Gedanken darüber machen, wie Rohdaten aufgenommen, gepflegt und innerhalb der Organisation über einen Katalog veröffentlicht werden können, den Data Scientists bei Bedarf für KI und ML nutzen können, während Compliance-Abteilungen dort Daten suchen und finden können.
Wie wichtig ist es, hier effiziente Prozesse zu schaffen, einschließlich eines zentralisierten Zugriffs auf Daten? Und wie können Unternehmen dies am besten angehen?
Es führt kein Weg daran vorbei, effiziente Prozesse zu etablieren und einen zentralen Zugriff auf Daten zu ermöglichen. Was nützen Informationen, die nicht gefunden werden? Intelligenz bedeutet in diesem Zusammenhang, zu wissen, was wo aufbewahrt wird, und die für Informationen jeweils angemessene Aufbewahrung zu kennen. Also zum Beispiel zu wissen, wer Zugang zu ihnen hat, wie lange sie aufbewahrt werden können oder müssen und welche Daten sie enthalten. Intelligenz ermöglicht ein sauberes Reporting über all diese Aktivitäten, aber auch die Beschreibung der Daten selbst durch Metadaten. Das Datenwachstum wird uns auf absehbare Zeit erhalten bleiben – genau wie die Sensibilität der in den Daten enthaltenen Informationen –, so dass der Bedarf an intelligent verwalteten Daten weiter zunehmen wird.
Heute ist es ein Muss, dass Organisationen, mit denen wir zusammenarbeiten, eine angemessene Governance für ihre Daten haben. Warum? Weil sie hochsensible Informationen über uns enthalten: unseren persönlichen Internet-Suchverlauf, die Kommunikation mit Freunden und Unternehmen, Sprachaufzeichnungen, unsere Versicherungs- oder Gesundheitsdaten und Finanzinformationen – alle diese Informationen sind Teil unseres digitalen Fußabdrucks. Ein falscher Umgang mit den persönlichen Daten bricht unser Vertrauen und mindert unsere Bereitschaft, zukünftig Geschäfte mit einem Unternehmen zu tätigen.
Welche möglichen Hindernisse, sowohl intern als auch extern, sehen Sie in diesem Zusammenhang? Wie groß ist das Problem von Abteilungs-Silos und des fehlenden einheitlichen Umgangs mit Daten?
Das Versäumnis, Daten zu zentralisieren, zu bereinigen, zu ergänzen, zu verwalten und zu regeln, macht sie weniger transparent, schwerer auffindbar, schwer zu kontrollieren und fast unmöglich zu integrieren.
Die Zentralisierung von Daten muss aber keine physische Zentralisierung erfordern, es sollte keine Rolle spielen, wo sich die Daten in einer Unternehmensstruktur befinden. Stattdessen geht es im modernen Rechenzentrum darum, eine zentrale Form der Kontrolle einzurichten. Mit Hilfe eines zentralisierten, intelligenten Daten-Hubs können IT-Verantwortliche den Datenzugriff, die Verwaltung und die Governance standardisieren und Anwendern mehr Komfort bieten, ohne die Sicherheit oder Compliance zu beeinträchtigen.
Wie steht es um die Qualität der Daten selbst? Wie kann diese verbessert werden und wie können Organisationen ermutigt werden, sie auf dem neuesten Stand zu halten?
Datenqualität ist ein wichtiger Teil jeder Lösung. Bei unstrukturierten Daten beispielsweise wird es wichtig, Struktur hinein zu bringen, also sie zu indizieren, anzureichern und so zu beschreiben, dass sie gesucht und gefunden werden können. Dateisysteme sammeln typischerweise nur wenige Datenpunkte über die gespeicherten Informationen, wie Dateiname, Dateityp, Erstellungs-, Änderungs- und Zugriffsdatum. Einige Anwendungen und Geräte wie Digitalkameras und Smartphones generieren zusätzliche oder benutzerdefinierte Metadaten, um den Inhalt der unstrukturierten Daten weiter zu beschreiben. Diese sind jedoch in der Regel in die Datei eingebettet, so dass sie verborgen sind und daher nicht ausreichend genutzt werden.
Praktisch alle Anbieter von Datenspeichern bieten heute irgendeine Form von Metadaten-Tagging an. Aber nur wenige verfügen über erweiterte Funktionen für die Anreicherung, Indizierung, Suche, Analyse oder metadatengesteuerte Disposition. Erst die Integration dieser Technologien schafft die Grundlage für einen Business Value durch umfangreiche Metadaten. Die Fähigkeit, Metadaten zur Beschreibung einer Datei, etwa einer Sprachaufzeichnung, zu verwenden, ist von entscheidender Bedeutung. Wenn ich in der Lage bin, die Kommunikation in eine Textdatei zu übersetzen und diese der Sprachaufnahme hinzufügen, kann ich sie einfach für Compliance-Zwecke suchen und finden.
So genannte »Pipeline-Tools« transformieren und standardisieren Daten, unabhängig von ihrer Herkunft. Sie stellen die Einhaltung von Formaten sicher und bewahren die Datenintegrität. Hier können Unternehmen an der Datenqualität arbeiten, während sie die Daten in den intelligenten Hub einspeisen. Die Integration bestehender und neuer Daten verbindet eine Vielzahl von internen und externen Datenquellen und vereinheitlicht Informationen, egal wo sie sich befinden.
Die Verwendung eines Katalogdienstes für strukturierte Daten kann Daten auch mithilfe fortschrittlicher KI indizieren, sie automatisch klassifizieren und Prinzipien zur Datenqualität anwenden
Unternehmen haben bekanntlich eine natürliche Abneigung gegen Veränderungen. Welche Argumente sprechen dafür, dass sie trotzdem einfach loslegen sollten?
Um sich für den Erfolg zu rüsten, muss sich ein Sponsor in der Organisation finden, der Initiativen mit Blick auf Geschäftsergebnisse vorantreibt. Das kann die Betriebseffizienz, eine Verbesserung der Produktivität, Kostensenkung, Gewinnsteigerung oder einfach ein Projekt betreffen, bei dem Daten der Schlüssel zum Erfolg sind, ein gutes Beispiel ist hier Compliance. Sobald diese Person oder dieses Projekt gefunden sind, kann der erste Schritt auf dem Weg zum datengestützten Unternehmen gemacht werden, indem Daten zu einem strategischen Aktivposten bei solchen Initiativen oder bei der Ansprache, Interaktion und Bindung von Kunden werden. Der Prozess braucht Zeit und die meisten datengetriebenen Unternehmen haben Jahre gebraucht, um dorthin zu gelangen, wo sie heute sind. Aber die Entwicklung ist auch alternativlos.
Welchen Risiken sind Unternehmen ausgesetzt, die dies nicht tun? Oder anders herum: welche Vorteile können Unternehmen erwarten, die ihre Aversion überwinden und effizientere Prozesse rund um Daten einführen?
Wenn Organisationen sich von einem analogen zu einem datengestützten und schließlich »data driven« Unternehmen entwickeln, werden sie Geld verdienen, Geld sparen und durch fundiertere Entscheidungen wettbewerbsfähiger bleiben.
Bei der Entwicklung zum datengetriebenen Unternehmen müssen drei wichtige Dinge beachtet werden: Die Technologie muss eine datengetriebene Kultur unterstützen und Daten für alle Mitarbeiter verfügbar machen, die Kultur sollte jeden dazu ermutigen, sich mit der Idee anzufreunden, Daten für Geschäftsentscheidungen auf jeder Ebene zu nutzen, und es muss eine Organisationsstruktur geben, die diese datengetriebene Kultur unterstützt.
Hitachi fasst dies unter dem Begriff DataOps zusammen. Darunter verstehen wir ein Management von Unternehmensdaten für die KI-Ära, das Datenkonsumenten mit Datenerzeugern verbindet, um die Zusammenarbeit und digitale Innovation zu beschleunigen. DataOps ist kein Produkt, keine Dienstleistung oder Lösung. Es ist eine Methodik, ein technologischer und kultureller Wandel, um die Datennutzung im Unternehmen durch bessere Datenqualität, kürzere Zykluszeiten und besseres Datenmanagement zu verbessern. Aus technologischer Sicht geht es darum, die richtigen Daten am richtigen Ort und zur richtigen Zeit zu haben.
185 Artikel zu "data driven"
NEWS | TRENDS KOMMUNIKATION | TRENDS MOBILE | TRENDS 2019 | MARKETING | SERVICES | TIPPS
Von Data-Driven zu Choice-First: Konsumenten eine Wahl bei der Datenverarbeitung geben
10. Juli 2019
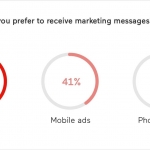
Lediglich jeder vierte Deutsche ist der Meinung, dass maßgeschneiderte Werbebotschaften auf Mobilgeräten nützlich sind. Jeder Dritte (35 Prozent) bekommt durch aufdringliche oder irrelevante Werbung einen schlechten Eindruck von der jeweiligen App oder Website. 75 Prozent der Deutschen empfinden maßgeschneiderte Werbung, die passende Produkte oder Services auf mobilen Devices zeigt, ausschließlich als nervig. Das geht…
STRATEGIEN | AUSGABE 7-8-2015
Data Analytics – Evolution zu einer Insight Driven Organisation
4. August 2015

Analytics ist die Evolution der Entscheidungsfindung. Unternehmen müssen einen informationsgetriebenen Entscheidungsfindungsprozess etablieren um in einer komplexeren Welt die richtigen Entscheidungen zu treffen.
NEWS | BUSINESS INTELLIGENCE | BUSINESS PROCESS MANAGEMENT | EFFIZIENZ | FAVORITEN DER REDAKTION | INFRASTRUKTUR | LÖSUNGEN
Robuste und widerstandsfähige Lieferketten: So hält Data Analytics die Supply Chain am Laufen
30. Juni 2020
Die rasche Verbreitung von Covid-19 hat viele Lieferketten unter Stress gesetzt. Hamsterkäufe und Produktionsstopps angesichts fehlender Rohstoffe machten es schwer, die Nachfrage der Märkte zu erfüllen. Da viele Branchen von Lieferungen aus anderen Ländern abhängig sind, müssen Entscheidungsträger in der Lage sein, schnell Anpassungen an der Supply Chain vorzunehmen. Dies funktioniert jedoch nur, wenn verlässliche…
NEWS | BUSINESS INTELLIGENCE | BUSINESS PROCESS MANAGEMENT | DIGITALISIERUNG | STRATEGIEN | AUSGABE 3-4-2019
Advanced, predictive, preventive: Data Analytics – Trend oder Zukunft?
8. April 2019

Die Themen Digitalisierung und Big Data stehen bereits seit Jahren auf der »To-do-Liste« der Unternehmen und sind auch in den Fachmedien mehr als präsent. Allerdings steckt die Umsetzung in der Realität bei vielen Unternehmen noch in den Kinderschuhen. Das Potenzial, das Daten bieten, ist häufig nicht auf den ersten Blick ersichtlich. Erst durch eine detaillierte Analyse der Daten lassen sich diese optimal nutzen. Mittlerweile eröffnen sich hier mit Data Analytics ganz neue Möglichkeiten.
NEWS | DIGITALISIERUNG | FAVORITEN DER REDAKTION | LÖSUNGEN | ONLINE-ARTIKEL
Wie Automatisierung des Data Warehouse den Wert der Unternehmensdaten erhöhen kann
26. März 2019

Volume, Velocity, Variety, Veracity. Im englischen IT-Sprachgebrauch haben sich die vier Vs der Datenspeicherung längst etabliert. Volumen, Geschwindigkeit, Vielfalt und Wahrhaftigkeit gilt es in Einklang zu bringen, um die Daten eines Unternehmens erfolgreich verwalten zu können. Herkömmliche Data-Warehouse-Infrastrukturen sind häufig nicht mehr in der Lage, die enormen Datenmengen, die Vielfalt der Datentypen, die Geschwindigkeit mit…
NEWS | BUSINESS INTELLIGENCE | TRENDS CLOUD COMPUTING | CLOUD COMPUTING | TRENDS SERVICES | TRENDS 2019 | KÜNSTLICHE INTELLIGENZ | SERVICES
»Data Analytics«-Markt: Machine Learning – Preise sinken, die Produktreife steigt
11. Dezember 2018
»Machine Learning as a Service« ist zu einem umkämpften Markt geworden, in dem sich nahezu alle wichtigen IT-Provider positionieren. Sie müssen die Funktionen, zugrundeliegenden Algorithmen und Modelle dabei qualitativ wie quantitativ schnell weiterentwickeln, um Marktanteile und Kunden zu gewinnen.
Read the full article